Data visualization and understanding
Using python, I was able to design a Graph using scatter plots to design a liner regression models.
This model showcases the survival Chace with different age groups during the Titanic.
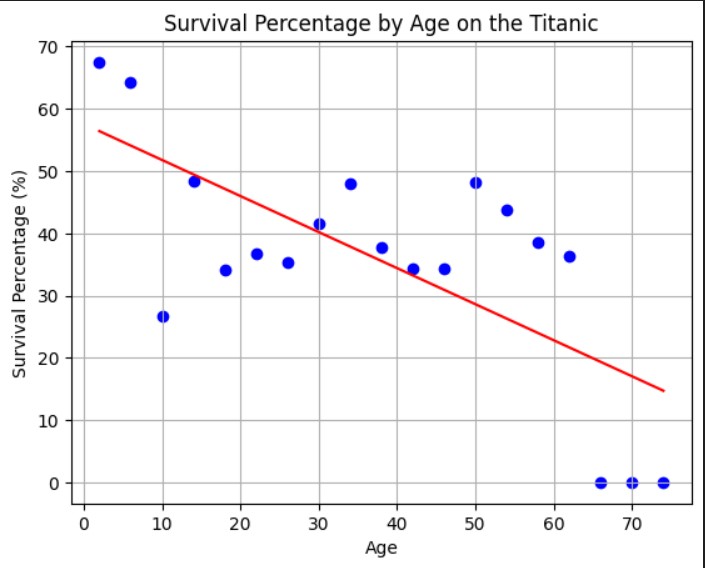
During the sinking of the Titanic, Women and children were the first to be on the life rafts, because of this as seen by the graph children had a higher survival chance. Class does also come into effect with this as 1st class were also the first to be released onto the life rafts.