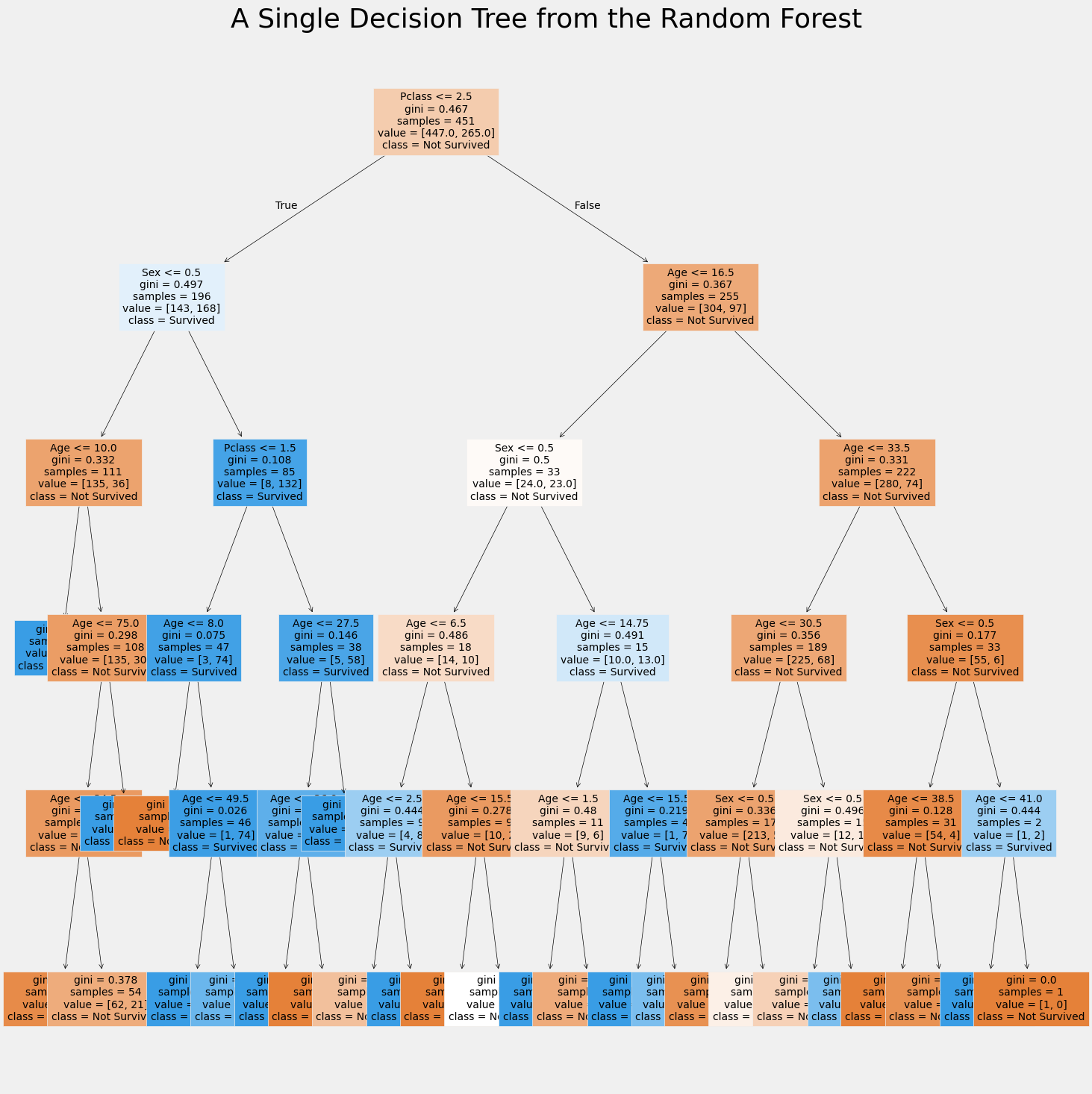
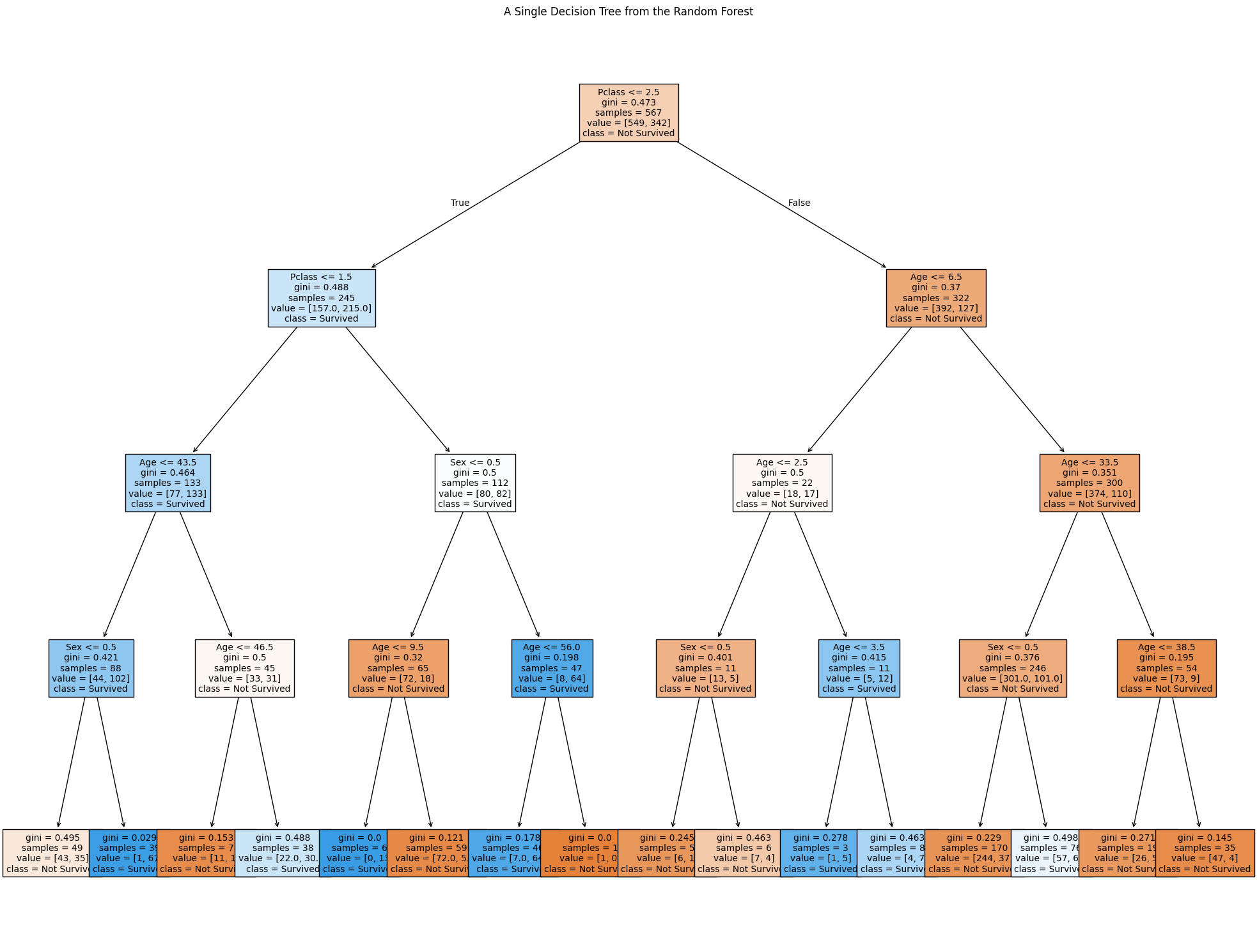
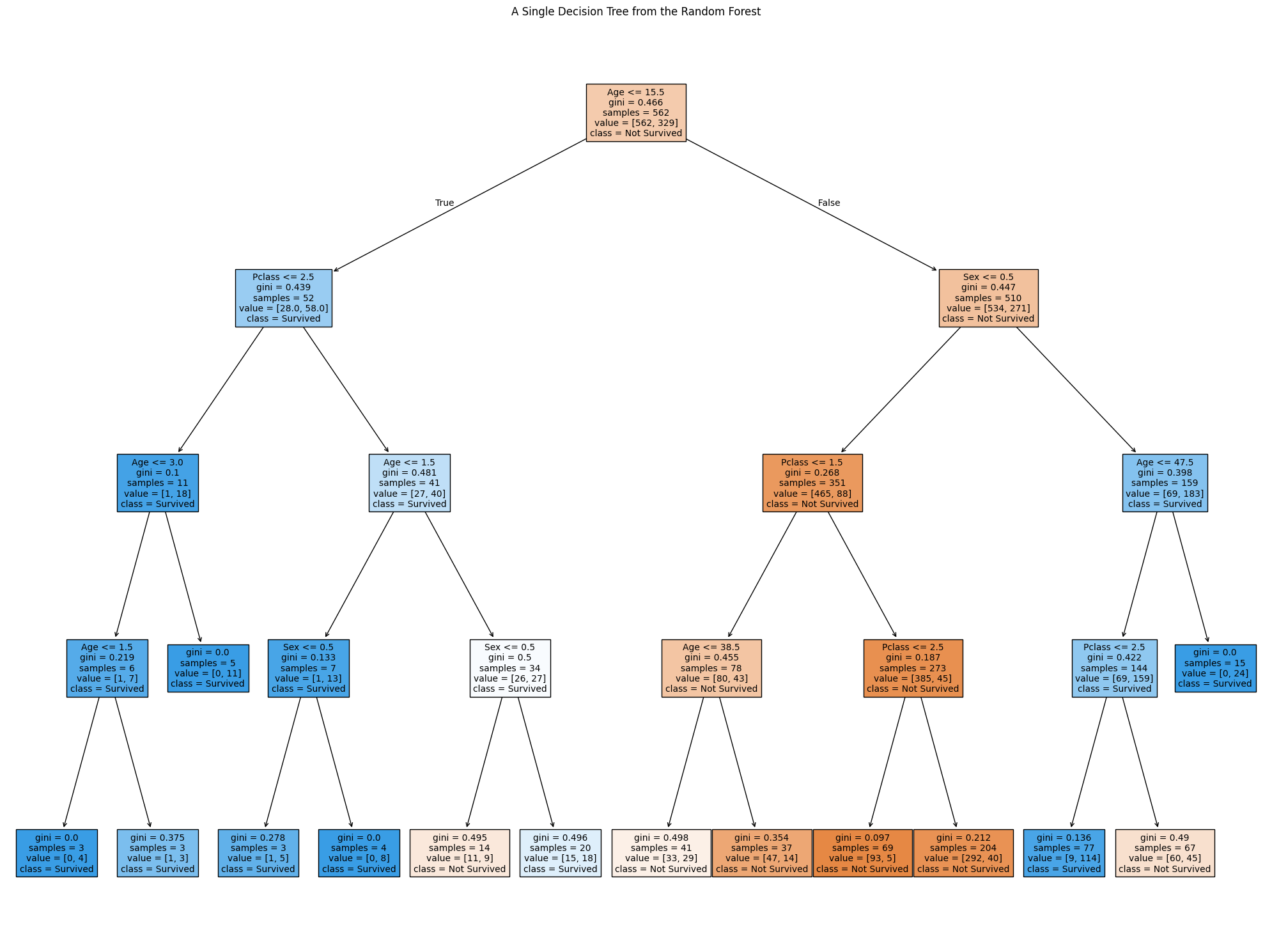
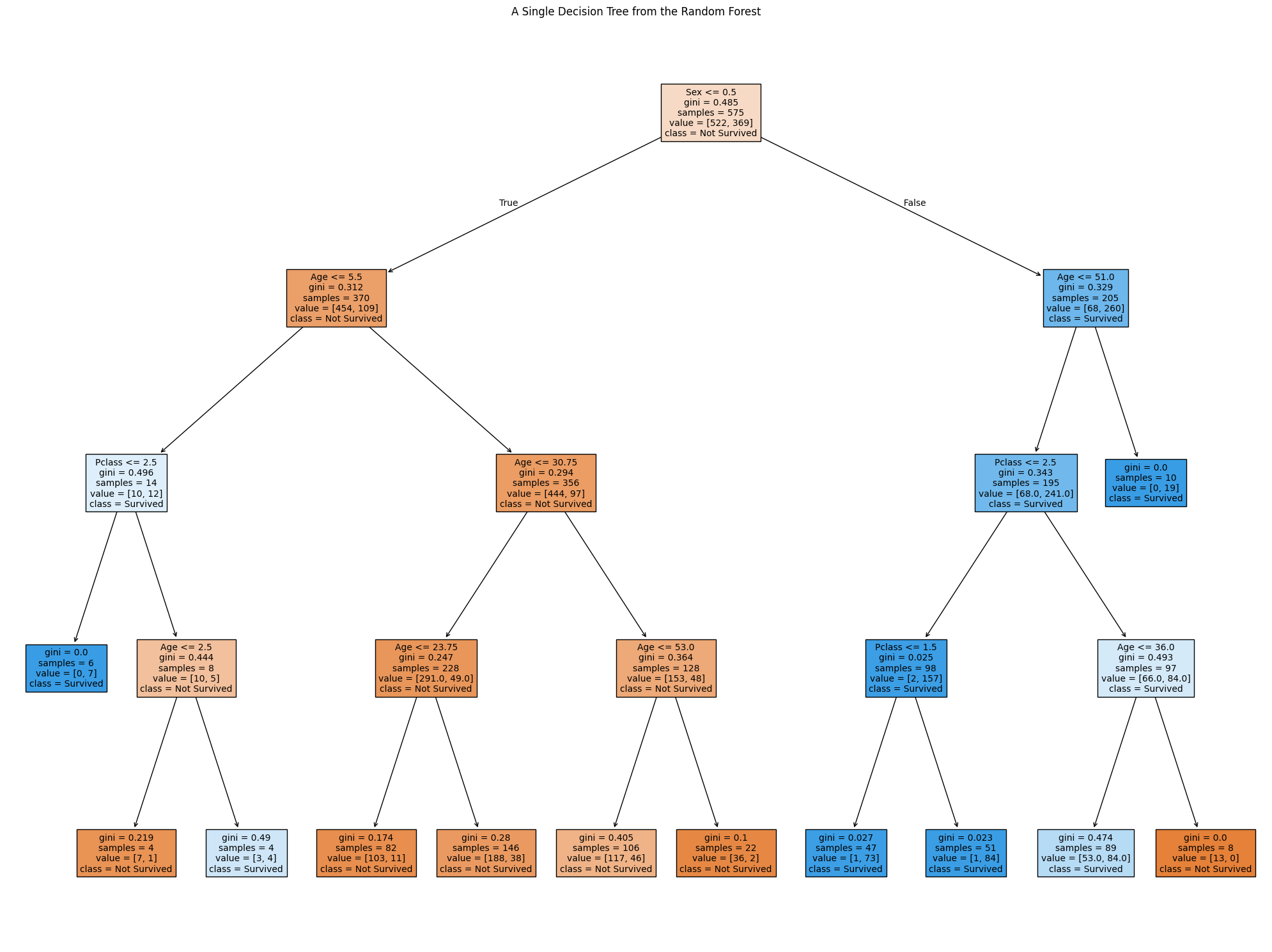
Data Visualization and Understanding
Using Python (jupiter Notebook) and Matplotlib, I visualized a single decision tree from the Random Forest model. This visualization highlights how individual trees in the Random Forest make decisions based on splits in the data.
The visualization shows splits based on features like gender, passenger class, and age, providing insight into the survival likelihood for different groups of passengers.
Below are different decision trees that I have gotten from running my random forest code, each one is different from the other