Data Visualization and Understanding
Using Python (Jupyter Notebook), I visualized the Decision Tree generated by the model to better understand how features influenced survival predictions.
The Decision Tree demonstrates splits in data based on features like gender, passenger class, and age to make predictions. These splits highlight the importance of certain variables in determining survival.
The images below showcase different decision trees from the random forest, each varying slightly from the others.
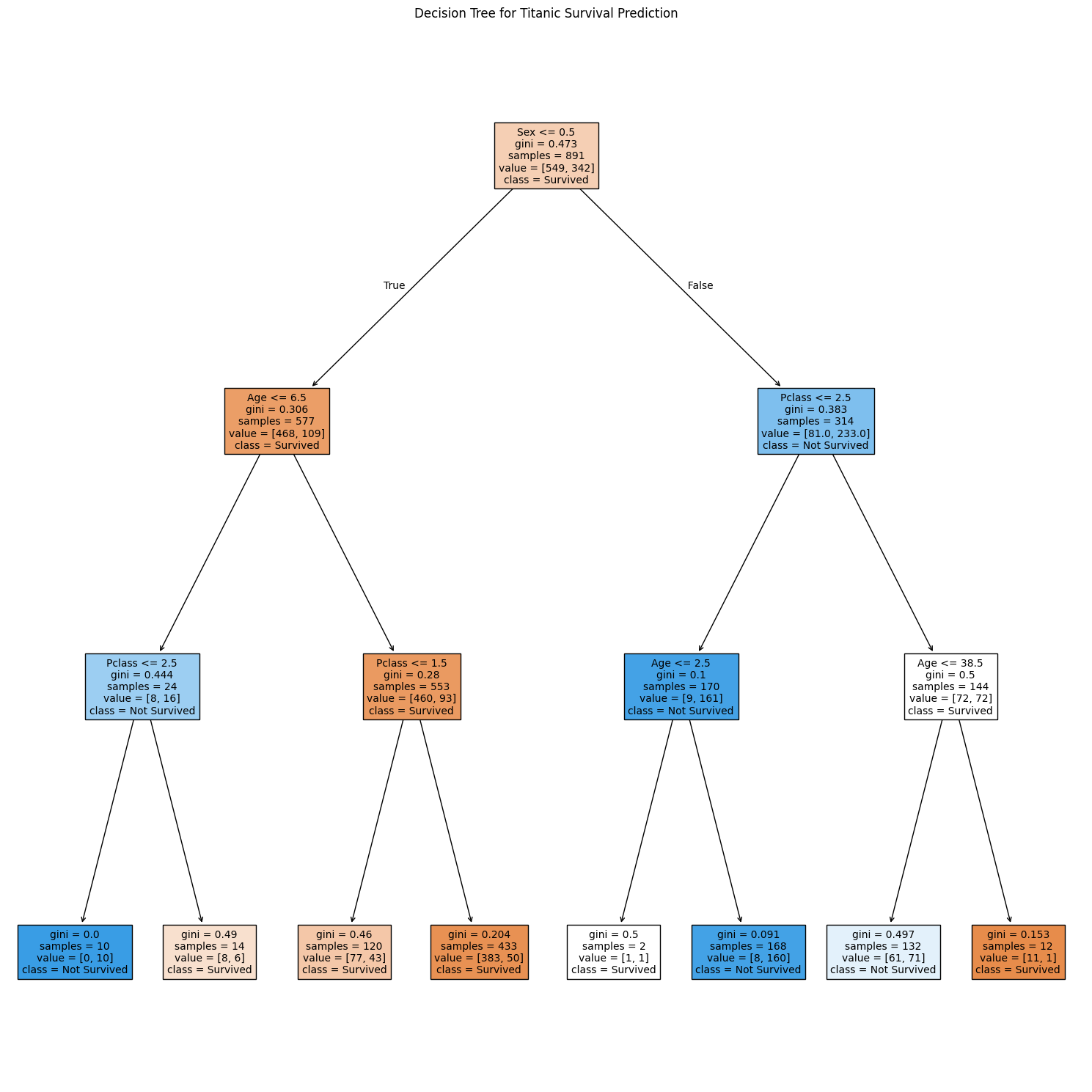
The visualization clearly shows how female passengers, children, and those in higher classes had better survival chances. This aligns with historical accounts of the Titanic disaster.